Publications
My publications and ongoing academic works in reversed chronological order.
2024
-
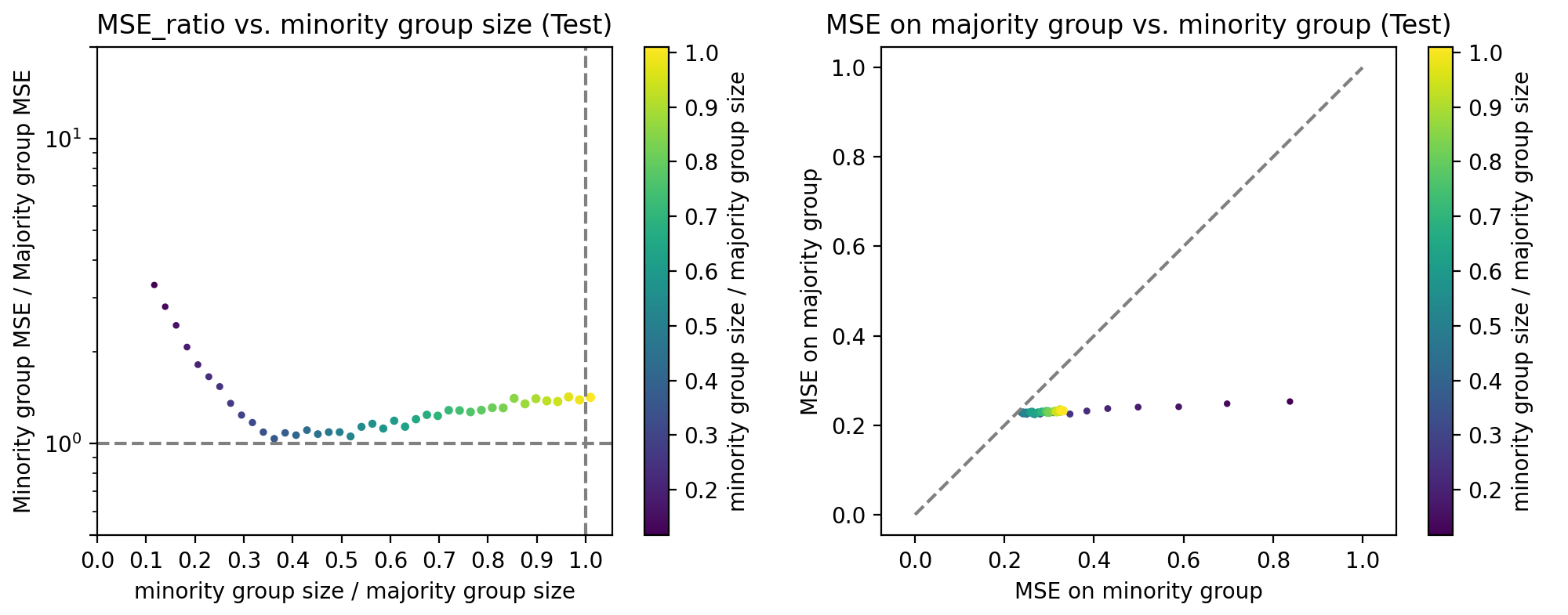 CATE Estimation with Imbalanced CovariatesLinan Zhao, and Stefan WagerStanford Digital Repository, 2024
CATE Estimation with Imbalanced CovariatesLinan Zhao, and Stefan WagerStanford Digital Repository, 2024Conditional average treatment effect (CATE) estimates have been increasingly used in policy decision-making as they can profile and prioritize individuals who receive the most benefits from a treatment. This paper studies the specific case of an imbalanced covariate in the data set. We posit that standard parametric and non-parametric methods lead to disparate performance for the minority and majority groups, creating bias in CATE estimates. In this paper, we first provide theoretical derivations for reweighting methods in a parametric setting, which will provide deeper intuitions about the problem. Then, we propose a repository of tools that address the issues of imbalanced covariates, including reweighting in causal forests and data augmentation through generative modeling. We demonstrate the effectiveness of these methods through extensive simulation studies. Finally, we apply these novel methods to a real-world data set in the case of job training programs.
@article{cate_imbalance, author = {Zhao, Linan and Wager, Stefan}, title = {{CATE Estimation with Imbalanced Covariates}}, journal = {Stanford Digital Repository}, year = {2024}, } -
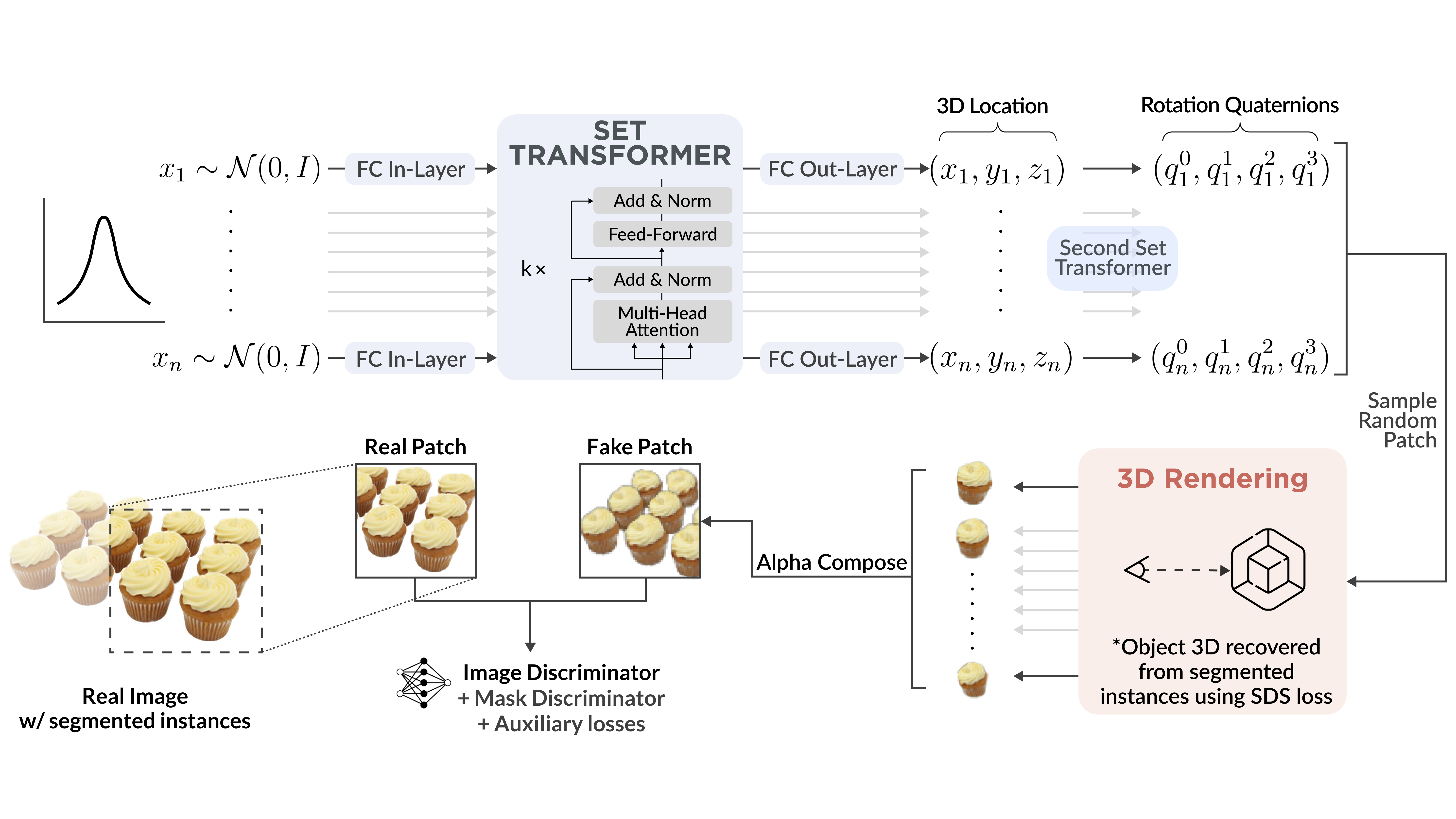 Learning Generative 3D Scene Layouts from a Single ImageLinan Zhao, Zeqing Yuan, Yunzhi Zhang, and 2 more authorsAI for 3D Generation Workshop, CVPR, 2024
Learning Generative 3D Scene Layouts from a Single ImageLinan Zhao, Zeqing Yuan, Yunzhi Zhang, and 2 more authorsAI for 3D Generation Workshop, CVPR, 2024What is a scene, conceptually? It can be decomposed into multiple objects, their spatial arrangement, and the background. While recent works have pushed the boundary on modeling 3D objects, the scene layout indicating how objects are arranged in 3D space remains under-explored. In this work, we build a generative model that learns the 3D scene layout distribution from a single 2D image, such as a photo of a parking lot containing several cars. We first retrieve the object geometry from segmented instances. Next, we build a permutation-equivariant model to generate layout parameters, which, combined with geometry, render scene images. We then leverage a patch-based discriminator on 2D images along with auxiliary losses to guide layout learning. Experiments demonstrate that our model successfully learns a wide range of layout distributions, each from a single Internet image. Our method achieves superior results on multiple downstream tasks, including extrapolating on number of instances and transferring learned layout to other objects.
@article{layout, author = {Zhao, Linan and Yuan, Zeqing and Zhang, Yunzhi and Wu, Shangzhe and Wu, Jiajun}, title = {{Learning Generative 3D Scene Layouts from a Single Image}}, journal = {AI for 3D Generation Workshop, CVPR}, year = {2024}, }


2023
-
 COMBOU: Leveraging Unlabeled Data in Conservative Offline Model-Based RLLinan Zhao, Haozhuo Li, Rafael Rafailov, and 1 more author2023
COMBOU: Leveraging Unlabeled Data in Conservative Offline Model-Based RLLinan Zhao, Haozhuo Li, Rafael Rafailov, and 1 more author2023@unpublished{ucombo, author = {Zhao, Linan and Li, Haozhuo and Rafailov, Rafael and Finn, Chelsea}, title = {{COMBOU: Leveraging Unlabeled Data in Conservative Offline Model-Based RL}}, year = {2023}, }

2022
-
 Using CNN and Spatial-Temporal Embedding for Predicting Smoke PM2.5Linan Zhao, Chenlin Meng, Stefano Ermon, and 2 more authors2022
Using CNN and Spatial-Temporal Embedding for Predicting Smoke PM2.5Linan Zhao, Chenlin Meng, Stefano Ermon, and 2 more authors2022@unpublished{smoke-cnn, author = {Zhao, Linan and Meng, Chenlin and Ermon, Stefano and Burke, Marshall and Lobell, David}, title = {{Using CNN and Spatial-Temporal Embedding for Predicting Smoke PM2.5}}, year = {2022}, }

2020
-
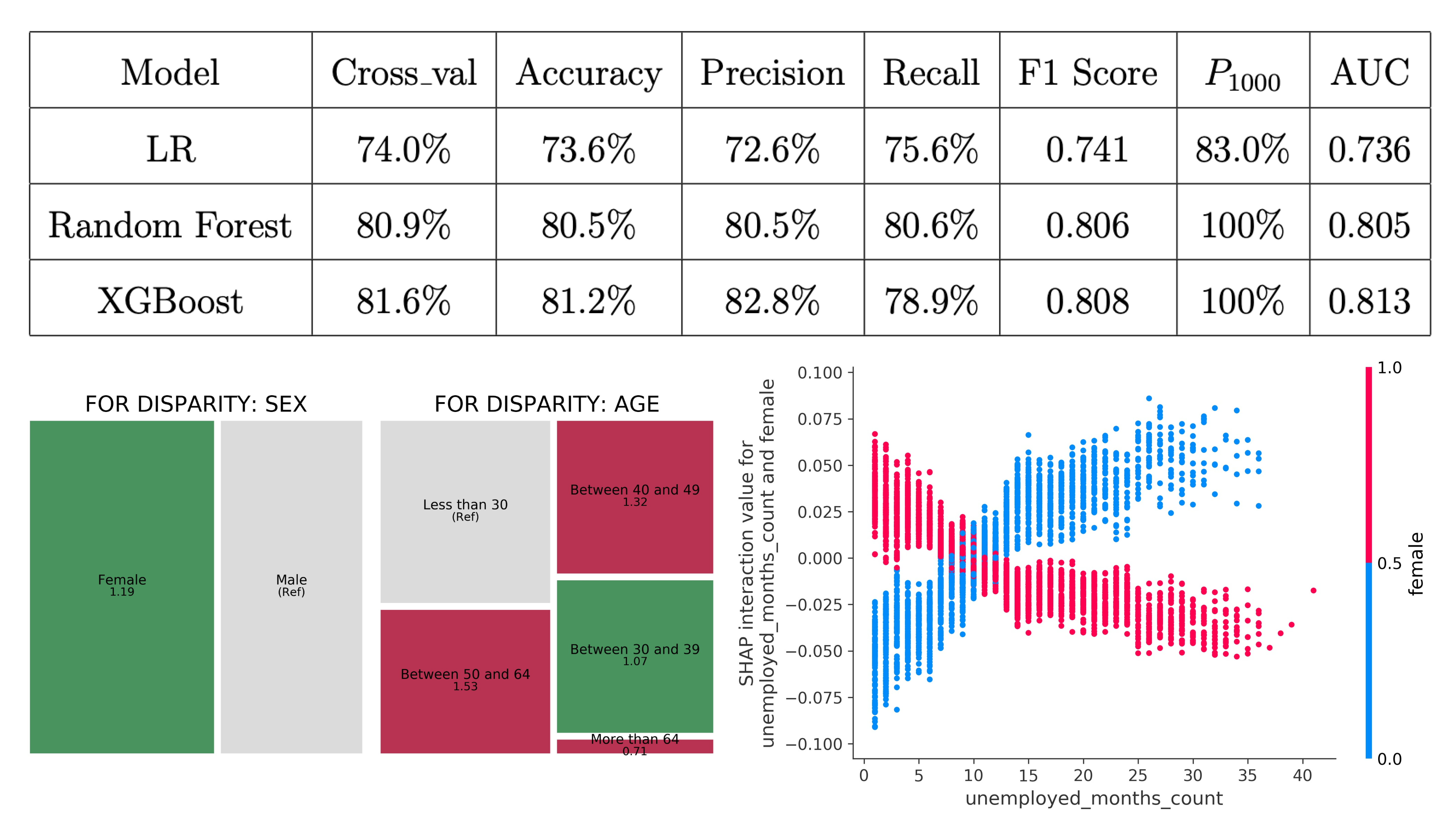 Data-Driven Approach for Predicting and Explaining the Risk of Long-Term UnemploymentLinan ZhaoIn E3S Web of Conferences, Dec 2020
Data-Driven Approach for Predicting and Explaining the Risk of Long-Term UnemploymentLinan ZhaoIn E3S Web of Conferences, Dec 2020Long-term unemployment has significant societal impact and is of particular concerns for policymakers with regard to economic growth and public finances. This paper constructs advanced ensemble machine learning models to predict citizens’ risks of becoming long-term unemployed using data collected from European public authorities for employment service. The proposed model achieves 81.2% accuracy on identifying citizens with high risks of long-term unemployment. This paper also examines how to dissect black-box machine learning models by offering explanations at both a local and global level using SHAP, a state-of-the-art model-agnostic approach to explain factors that contribute to long-term unemployment. Lastly, this paper addresses an under-explored question when applying machine learning in the public domain, that is, the inherent bias in model predictions. The results show that popular models such as gradient boosted trees may produce unfair predictions against senior age groups and immigrants. Overall, this paper sheds light on the recent increasing shift for governments to adopt machine learning models to profile and prioritize employment resources to reduce the detrimental effects of long-term unemployment and improve public welfare.
@inproceedings{LTU, author = {Zhao, Linan}, title = {{Data-Driven Approach for Predicting and Explaining the Risk of Long-Term Unemployment}}, booktitle = {E3S Web of Conferences}, year = {2020}, volume = {214}, month = dec, eid = {01023}, pages = {01023}, doi = {10.1051/e3sconf/202021401023}, adsurl = {https://ui.adsabs.harvard.edu/abs/2020E3SWC.21401023Z}, adsnote = {Provided by the SAO/NASA Astrophysics Data System}, }
